1. 들어가기
지난 글에 이어, 이번 글에서는 Oracle 계층형 쿼리에서 활용할 수 있는 연산자와 절(clause)에 대해 알아봅니다.
세부 주제는 다음과 같습니다.
- CONNECT BY 절 실행 순서
- CONNECT_BY_ROOT 연산자
- CONNECT_BY_ISLEAF 연산자
- SYS_CONNECT_BY_PATH 연산자
- ORDER SIBLINGS BY 절
2. 계층형 쿼리의 논리적 실행 순서: JOIN, CONNECT BY, WHERE
우리가 실제로 쓰는 대부분의 쿼리는 WHERE 절을 포함합니다. 그렇다면 CONNECT BY 절이 있는 계층형 쿼리에서는 WHERE 절을 어떻게 사용해야 할까요? Oracle 공식 문서에 따르면, 계층형 쿼리에서 각 절은 다음 순서로 처리됩니다.
- 테이블 간 JOIN에 사용되는 WHERE 절
- CONNECT BY 절
- 그 외 WHERE 절
(링크: https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/Hierarchical-Queries.html#GUID-0118DF1D-B9A9-41EB-8556-C6E7D6A5A84E'Oracle processes hierarchical queries as follows:...'로 시작하는 문단 참고)
예시를 확인하기 위해 추가로 DEPT 테이블을 생성하고, EMP 테이블에는 DEPT_CODE 컬럼을 추가합니다.
-- EMP 테이블에 DEPT_CODE 컬럼 추가
ALTER TABLE EMP ADD DEPT_CODE NUMBER;
-- EMP 테이블 각 레코드의 DEPT_CODE 값 업데이트
UPDATE EMP SET DEPT_CODE = 1 WHERE ID = 1;
-- 2번과 그 직간접 부하 직원은 모두 DEPT_CODE = 2
UPDATE EMP SET DEPT_CODE = 2 WHERE ID = 2;
UPDATE EMP SET DEPT_CODE = 2 WHERE ID IN (
SELECT ID FROM EMP WHERE ID != 2 CONNECT BY PRIOR ID = MANAGER_ID START WITH ID = 2
);
-- 2번과 그 직간접 부하 직원은 모두 DEPT_CODE = 3
UPDATE EMP SET DEPT_CODE = 3 WHERE ID = 3;
UPDATE EMP SET DEPT_CODE = 3 WHERE ID IN (
SELECT ID FROM EMP WHERE ID != 3 CONNECT BY PRIOR ID = MANAGER_ID START WITH ID = 3
);
-- DEPT 테이블 생성
CREATE TABLE DEPT (
DEPT_CODE number,
name varchar2(100),
CONSTRAINT PK_DEPT PRIMARY KEY(DEPT_CODE )
);
INSERT INTO DEPT VALUES (1, 'HEAD');
INSERT INTO DEPT VALUES (2, 'Sales');
INSERT INTO DEPT VALUES (3, 'Development');
1번 직원(총책임에 해당하는 'HEAD')과 Sales 부서에 해당하는 직원을 조회하는 계층형 쿼리를 실행해 봅시다.
SELECT
id, emp.name, manager_id, dept.dept_code, dept.name, LEVEL
FROM emp, dept
WHERE emp.dept_code = dept.dept_code
AND dept.name IN ('HEAD', 'Sales')
CONNECT BY
PRIOR id = manager_id
START WITH id = 1;
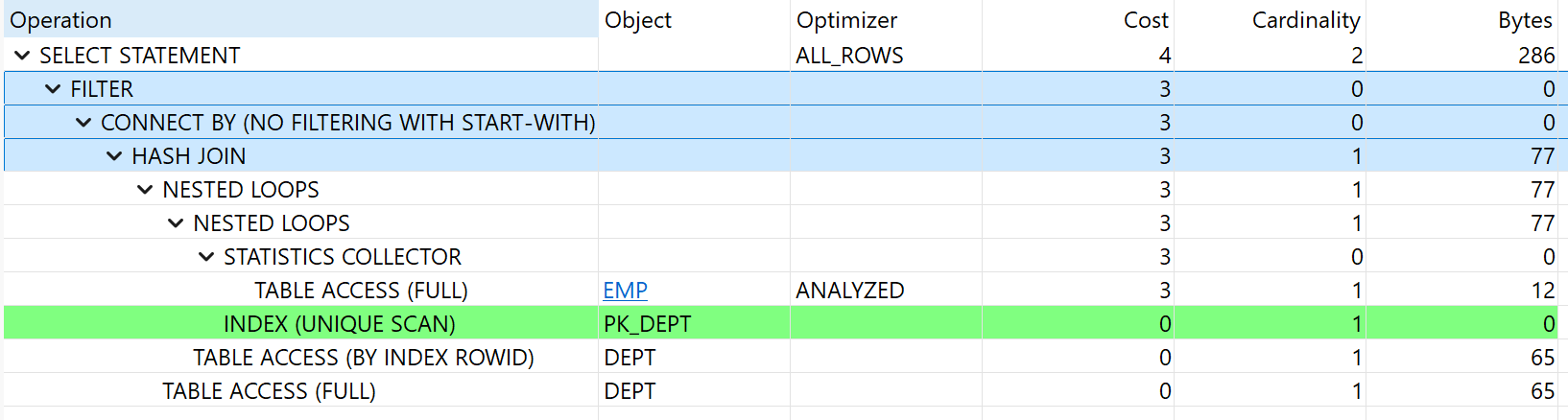
위 SQL의 실행계획은 다음과 같습니다. (DBeaver에서 조회) EMP와 DEPT 테이블 간 조회를 위한 HASH JOIN이 가장 먼저 실행되고, 그 다음 CONNECT BY 작업이, 마지막으로는 WHERE 절의 FILTER 작업이 실행되고 있습니다다.
위 쿼리 결과는 다음과 같습니다.
ID|NAME |MANAGER_ID|DEPT_CODE|NAME |LEVEL|
--+------+----------+---------+-----+-----+
1|EMP_1 | 0| 1|HEAD | 1|
2|EMP_2 | 1| 2|Sales| 2|
4|EMP_4 | 2| 2|Sales| 3|
8|EMP_8 | 4| 2|Sales| 4|
9|EMP_9 | 4| 2|Sales| 4|
5|EMP_5 | 2| 2|Sales| 3|
10|EMP_10| 5| 2|Sales| 4|
11|EMP_11| 5| 2|Sales| 4|
그런데 만약 가장 말단의 직원(LEVEL = 4)은 결과에서 제외하고 싶다면 어떻게 하면 될까요? WHERE 절에 조건을 추가하면 됩니다. CONNECT BY 절이 먼저 평가/실행되고 그 다음 WHERE 절이 적용되기 때문에, 계층형 쿼리 결과로 값이 정해지는 'LEVEL' 컬럼을 가지고도 필터링을 할 수 있습니다.
SELECT
id, name, manager_id, LEVEL
FROM EMP
WHERE LEVEL <> 4 -- 말단 직원을 결과에서 필터링
AND dept.name IN ('HEAD', 'Sales')
CONNECT BY manager_id = PRIOR id
START WITH id in 1;
결과는 아래와 같습니다. LEVEL = 4에 해당하는 말단 직원이 결과에서 제외되었습니다.
ID|NAME |MANAGER_ID|DEPT_CODE|NAME |LEVEL|
--+-----+----------+---------+-----+-----+
1|EMP_1| 0| 1|HEAD | 1|
2|EMP_2| 1| 2|Sales| 2|
4|EMP_4| 2| 2|Sales| 3|
5|EMP_5| 2| 2|Sales| 3|
CONNECT BY 절과 WHERE 절의 실행순서를 고려하면 불필요한 WHERE 절을 제거할 수도 있습니다. 우선, 위에서 실행했던 쿼리를 다시 한 번 보겠습니다.
SELECT
id, emp.name, manager_id, dept.dept_code, dept.name, LEVEL
FROM emp, dept
WHERE emp.dept_code = dept.dept_code
AND dept.name IN ('HEAD', 'Sales')
CONNECT BY
PRIOR id = manager_id
START WITH id = 1;
위 쿼리는 전 직원의 계층 관계를 CONNECT BY 절에서 먼저 평가하고, 그 전체 결과에 대해 부서 이름을 기준으로 필터링 하고 있습니다. 하지만 애초부터 우리가 궁금한 내용(총책임 및 영업부서 직원들)에 대해서만 계층 관계를 계산하게 하면, 연산의 효율성이 조금은 더 높아지지 않을까요?
SELECT
id, emp.name, manager_id, dept.dept_code, dept.name, LEVEL
FROM emp, dept
WHERE emp.dept_code = dept.dept_code
CONNECT BY
PRIOR id = manager_id AND DEPT.NAME IN ('HEAD', 'Sales')
START WITH id = 1;
두 쿼리는 똑같은 결과를 반환합니다. 하지만 실행계획은 서로 다릅니다. 두 번째 쿼리의 경우, WHERE 절에 의한 FILTER 작업이 수행되지 않습니다.

이와 같이 효율적으로 수행되는 계층형 쿼리를 작성하기 위해서는 이와 같은 WHERE 절, CONNECT BY 절의 실행 순서를 참고할 필요가 있습니다.
3. 계층형 쿼리 연산자
3.1. CONNECT_BY_ROOT 연산자
CONNECT_BY_ROOT는 root row의 컬럼을 참조하기 위해 사용되는 연산자입니다.
1번 직원을 루트로 하여 조회하는 계층형 쿼리에서, 각 행에 루트 행의 'name' 컬럼 값을 표시하고자 하면 다음과 같이 SQL문을 작성하면 됩니다.
SELECT
id,
name,
manager_id,
LEVEL,
CONNECT_BY_ROOT name AS ROOT_NAME -- 루트 행의 'name' 컬럼 값
FROM EMP
CONNECT BY manager_id = PRIOR id
START WITH id IN (1);
ID|NAME |MANAGER_ID|LEVEL|ROOT_NAME|
--+------+----------+-----+---------+
1|EMP_1 | 0| 1|EMP_1 |
2|EMP_2 | 1| 2|EMP_1 |
4|EMP_4 | 2| 3|EMP_1 |
8|EMP_8 | 4| 4|EMP_1 |
9|EMP_9 | 4| 4|EMP_1 |
5|EMP_5 | 2| 3|EMP_1 |
10|EMP_10| 5| 4|EMP_1 |
11|EMP_11| 5| 4|EMP_1 |
3|EMP_3 | 1| 2|EMP_1 |
6|EMP_6 | 3| 3|EMP_1 |
12|EMP_12| 6| 4|EMP_1 |
13|EMP_13| 6| 4|EMP_1 |
7|EMP_7 | 3| 3|EMP_1 |
14|EMP_14| 7| 4|EMP_1 |
15|EMP_15| 7| 4|EMP_1 |
CONNECT_BY_ROOT 연산자는 단항 연산자(unary operator)입니다. 따라서 루트 행의 여러 컬럼을 합쳐서 조회하고 싶으면, 이들을 괄호로 묶어서 하나의 식으로 표현해야 합니다.
SELECT
id,
name,
manager_id,
LEVEL,
CONNECT_BY_ROOT ('Name: ' || name || ', ID: ' || id ) AS ROOT_NAME -- 루트 행의 'name' 컬럼 값
FROM EMP
CONNECT BY manager_id = PRIOR id
START WITH id IN (1);
ID|NAME |MANAGER_ID|LEVEL|ROOT_NAME |
--+------+----------+-----+------------------+
1|EMP_1 | 0| 1|Name: EMP_1, ID: 1|
2|EMP_2 | 1| 2|Name: EMP_1, ID: 1|
4|EMP_4 | 2| 3|Name: EMP_1, ID: 1|
8|EMP_8 | 4| 4|Name: EMP_1, ID: 1|
9|EMP_9 | 4| 4|Name: EMP_1, ID: 1|
5|EMP_5 | 2| 3|Name: EMP_1, ID: 1|
10|EMP_10| 5| 4|Name: EMP_1, ID: 1|
11|EMP_11| 5| 4|Name: EMP_1, ID: 1|
3|EMP_3 | 1| 2|Name: EMP_1, ID: 1|
6|EMP_6 | 3| 3|Name: EMP_1, ID: 1|
12|EMP_12| 6| 4|Name: EMP_1, ID: 1|
13|EMP_13| 6| 4|Name: EMP_1, ID: 1|
7|EMP_7 | 3| 3|Name: EMP_1, ID: 1|
14|EMP_14| 7| 4|Name: EMP_1, ID: 1|
15|EMP_15| 7| 4|Name: EMP_1, ID: 1|
3.2. CONNECT_BY_ISLEAF 연산자
CONNECT_BY_ISLEAF 연산자는 계층형 쿼리의 결과에서 이 행이 계층 관계의 가장 말단, 즉 잎 노드(leaf node)에 해당하는지 여부를 참(1)과 거짓(0)으로 반환하는 연산자입니다.
SELECT
id, name, manager_id, LEVEL,
CASE WHEN connect_by_isleaf = 0 THEN 'No' ELSE 'Yes' END AS isleaf
FROM EMP
CONNECT BY manager_id = PRIOR id
START WITH id in 1;
위 쿼리를 조회하면, 다음과 같이 계층 가장 아래의 직원들(LEVEL 4 직원들)에 대해서만 ISLEAF 컬럼 값이 'No'로 출력됩니다.
ID|NAME |MANAGER_ID|LEVEL|ISLEAF|
--+------+----------+-----+------+
1|EMP_1 | 0| 1|No |
2|EMP_2 | 1| 2|No |
4|EMP_4 | 2| 3|No |
8|EMP_8 | 4| 4|Yes |
9|EMP_9 | 4| 4|Yes |
5|EMP_5 | 2| 3|No |
10|EMP_10| 5| 4|Yes |
11|EMP_11| 5| 4|Yes |
3|EMP_3 | 1| 2|No |
6|EMP_6 | 3| 3|No |
12|EMP_12| 6| 4|Yes |
13|EMP_13| 6| 4|Yes |
7|EMP_7 | 3| 3|No |
14|EMP_14| 7| 4|Yes |
15|EMP_15| 7| 4|Yes |
3.3. SYS_CONNECT_BY_PATH 함수
SYS_CONNECT_BY_PATH 함수는 루트 행에서 현재 행까지 조회되는 값을 이어서 붙여주는 역할을 합니다.
예를 들어 최상위 직원으로부터 각 직원까지 업무가 하달될 때 거치는 직원의 순서를 확인하고 싶다면, 아래와 같이 계층형 쿼리를 작성하면 됩니다. SYS_CONNECT_BY_PATH 함수의 두 번째 인자로 슬래시(/) 문자를 넣어서 각 직원의 이름이 구분되도록 합니다.
SELECT
id,
name,
manager_id,
LEVEL,
SYS_CONNECT_BY_PATH(name, '/') AS DIRECTION_CHAIN
FROM EMP
CONNECT BY PRIOR id = manager_id
START WITH id IN (1);
ID|NAME |MANAGER_ID|LEVEL|DIRECTION_CHAIN |
--+------+----------+-----+-------------------------+
1|EMP_1 | 0| 1|/EMP_1 |
2|EMP_2 | 1| 2|/EMP_1/EMP_2 |
4|EMP_4 | 2| 3|/EMP_1/EMP_2/EMP_4 |
8|EMP_8 | 4| 4|/EMP_1/EMP_2/EMP_4/EMP_8 |
9|EMP_9 | 4| 4|/EMP_1/EMP_2/EMP_4/EMP_9 |
5|EMP_5 | 2| 3|/EMP_1/EMP_2/EMP_5 |
10|EMP_10| 5| 4|/EMP_1/EMP_2/EMP_5/EMP_10|
11|EMP_11| 5| 4|/EMP_1/EMP_2/EMP_5/EMP_11|
3|EMP_3 | 1| 2|/EMP_1/EMP_3 |
6|EMP_6 | 3| 3|/EMP_1/EMP_3/EMP_6 |
12|EMP_12| 6| 4|/EMP_1/EMP_3/EMP_6/EMP_12|
13|EMP_13| 6| 4|/EMP_1/EMP_3/EMP_6/EMP_13|
7|EMP_7 | 3| 3|/EMP_1/EMP_3/EMP_7 |
14|EMP_14| 7| 4|/EMP_1/EMP_3/EMP_7/EMP_14|
15|EMP_15| 7| 4|/EMP_1/EMP_3/EMP_7/EMP_15|
참고로 SYS_CONNECT_BY_PATH의 첫 번째 파라미터로 컬럼 이름 하나만 들어가는 것은 아니고, 하나의 값으로 환원될 수 있는 식을 전달할 수 있습니다. 예를 들면 다음과 같이 작성할 수도 있습니다.
SELECT
id,
name,
manager_id,
LEVEL,
SYS_CONNECT_BY_PATH(name || '(' || id || ')', '/') AS DIRECTION_CHAIN
FROM EMP
CONNECT BY PRIOR id = manager_id
START WITH id IN (1);
ID|NAME |MANAGER_ID|LEVEL|DIRECTION_CHAIN |
--+------+----------+-----+--------------------------------------+
1|EMP_1 | 0| 1|/EMP_1(1) |
2|EMP_2 | 1| 2|/EMP_1(1)/EMP_2(2) |
4|EMP_4 | 2| 3|/EMP_1(1)/EMP_2(2)/EMP_4(4) |
8|EMP_8 | 4| 4|/EMP_1(1)/EMP_2(2)/EMP_4(4)/EMP_8(8) |
9|EMP_9 | 4| 4|/EMP_1(1)/EMP_2(2)/EMP_4(4)/EMP_9(9) |
5|EMP_5 | 2| 3|/EMP_1(1)/EMP_2(2)/EMP_5(5) |
10|EMP_10| 5| 4|/EMP_1(1)/EMP_2(2)/EMP_5(5)/EMP_10(10)|
11|EMP_11| 5| 4|/EMP_1(1)/EMP_2(2)/EMP_5(5)/EMP_11(11)|
3|EMP_3 | 1| 2|/EMP_1(1)/EMP_3(3) |
6|EMP_6 | 3| 3|/EMP_1(1)/EMP_3(3)/EMP_6(6) |
12|EMP_12| 6| 4|/EMP_1(1)/EMP_3(3)/EMP_6(6)/EMP_12(12)|
13|EMP_13| 6| 4|/EMP_1(1)/EMP_3(3)/EMP_6(6)/EMP_13(13)|
7|EMP_7 | 3| 3|/EMP_1(1)/EMP_3(3)/EMP_7(7) |
14|EMP_14| 7| 4|/EMP_1(1)/EMP_3(3)/EMP_7(7)/EMP_14(14)|
15|EMP_15| 7| 4|/EMP_1(1)/EMP_3(3)/EMP_7(7)/EMP_15(15)|
4. 계층형 쿼리의 결과 정렬: ORDER SIBLINGS BY
ORDER SIBLINGS BY 절을 살펴보기 전에 미리 알아두어야 하는 점은, 일단 계층형 쿼리에서 반환하는 결과 자체가 부모 행 아래 자식 행이 재귀적으로 나타나는 형식으로, 어느 정도는 정렬이 되어 있다는 것입니다.
SELECT
id,
name,
manager_id,
LEVEL
FROM EMP
CONNECT BY PRIOR id = manager_id
START WITH id IN (1);
ID|NAME |MANAGER_ID|LEVEL|
--+------+----------+-----+
1|EMP_1 | 0| 1|
2|EMP_2 | 1| 2|
4|EMP_4 | 2| 3|
8|EMP_8 | 4| 4|
9|EMP_9 | 4| 4|
5|EMP_5 | 2| 3|
10|EMP_10| 5| 4|
11|EMP_11| 5| 4|
3|EMP_3 | 1| 2|
6|EMP_6 | 3| 3|
12|EMP_12| 6| 4|
13|EMP_13| 6| 4|
7|EMP_7 | 3| 3|
14|EMP_14| 7| 4|
15|EMP_15| 7| 4|
ORDER SIBLINGS BY 절에는 형제 행들, 즉, 부모 행이 같은 서로 다른 행들을 어떻게 정렬할지에 대한 기준이 기술되어야 합니다. 예를 들어, LEVEL이 같은(즉, 부모 행이 같은) 직원에 대해서는 부서명 오름차순으로 표시하고 싶다면 다음과 같이 쿼리를 작성하면 됩니다.
SELECT
id,
EMP.name,
manager_id,
LEVEL,
DEPT.NAME
FROM EMP, DEPT
WHERE EMP.DEPT_CODE = DEPT.DEPT_CODE
CONNECT BY PRIOR id = manager_id
START WITH id IN (1)
ORDER SIBLINGS BY DEPT.NAME ASC;
ID|NAME |MANAGER_ID|LEVEL|NAME |
--+------+----------+-----+-----------+
1|EMP_1 | 0| 1|HEAD |
3|EMP_3 | 1| 2|Development| -- 'Sales'보다 'Development'가 사전상 앞서기 때문에 LEVEL이 같은 직원2보다 먼저 나타남.
6|EMP_6 | 3| 3|Development|
12|EMP_12| 6| 4|Development|
13|EMP_13| 6| 4|Development|
7|EMP_7 | 3| 3|Development|
14|EMP_14| 7| 4|Development|
15|EMP_15| 7| 4|Development|
2|EMP_2 | 1| 2|Sales |
4|EMP_4 | 2| 3|Sales |
8|EMP_8 | 4| 4|Sales |
9|EMP_9 | 4| 4|Sales |
5|EMP_5 | 2| 3|Sales |
10|EMP_10| 5| 4|Sales |
11|EMP_11| 5| 4|Sales |
결과에서도 확인되지만 ORDER SIBLINGS BY로 정렬해도 부모 행 아래에 자식 행이 나타나는 형식은 유지됩니다.
즉, 어떤 부모 행이 직계 자식 행을 여럿 가지고 있을 경우, 그 중 하나의 직계 자식 행을 골라서 여기 속하는 다른 자식 행을 끝까지 표시하고, 그러고 나서야 다른 직계 자식 행에 대해서 똑같은 작업을 하는 것입니다.
이러한 작업은 프로그래밍으로 치면 깊이우선탐색 같은 것이고, ORDER SIBLINGS BY 절에는 이러한 깊이우선탐색을 실행할 때 어떤 순서로 직계 자식 행을 선택(표시)할지에 대해서 기술해야 하는 것이지요.
만약 각 행의 LEVEL 순서 오름차순으로 정렬하고 싶다면 어떻게 해야 할까요?
그때에는 평범한 ORDER BY 절을 사용하면 됩니다.
SELECT
id,
EMP.name,
manager_id,
LEVEL,
DEPT.NAME
FROM EMP, DEPT
WHERE EMP.DEPT_CODE = DEPT.DEPT_CODE
CONNECT BY PRIOR id = manager_id
START WITH id IN (1)
ORDER BY LEVEL, id;
ID|NAME |MANAGER_ID|LEVEL|NAME |
--+------+----------+-----+-----------+
1|EMP_1 | 0| 1|HEAD |
2|EMP_2 | 1| 2|Sales |
3|EMP_3 | 1| 2|Development|
4|EMP_4 | 2| 3|Sales |
5|EMP_5 | 2| 3|Sales |
6|EMP_6 | 3| 3|Development|
7|EMP_7 | 3| 3|Development|
8|EMP_8 | 4| 4|Sales |
9|EMP_9 | 4| 4|Sales |
10|EMP_10| 5| 4|Sales |
11|EMP_11| 5| 4|Sales |
12|EMP_12| 6| 4|Development|
13|EMP_13| 6| 4|Development|
14|EMP_14| 7| 4|Development|
15|EMP_15| 7| 4|Development|
5. 나가기
이상 계층형 쿼리의 논리적 실행 순서, 활용 가능한 연산자, 정렬 방법에 대해서 알아 보았습니다.
다음 글에서는 계층형 쿼리에서의 순환(사이클) 탐지/처리 방법에 대해서 알아 보겠습니다. 계층형 데이터는 정의상 순환 관계를 갖지 않아야 하므로, 사이클 처리 역시 계층형 쿼리를 다룰 때 주요하게 고려해야 하는 부분입니다.
오류에 대한 지적이나 질문은 댓글로 남겨 주세요. 감사합니다.
'SQL' 카테고리의 다른 글
| [Oracle] 계층형 쿼리 (1) (CONNECT BY, START WITH, PRIOR) (0) | 2025.09.15 |
|---|