1. 들어가기: 계층형 구조(hierarchical structure)란?
어떤 데이터의 집합이 계층구조를 가진다는 건 무슨 뜻일까요? 각 데이터의 높고 낮음, 또는 앞서고 뒤따름을 구분하는 기준이 하나 이상 존재하며, 이를 바탕으로 데이터를 조직화 할 수 있다는 뜻일 겁니다.

이러한 계층형 구조는 인간의 일상 생활에서 쉽게 찾을 수 있습니다. 조직의 지시/보고 체계, 회사 간 지배구조 등, 그래서 흔히 계층구조를 '피라미드형 구조'라고 부르기도 합니다. 가장 높은 등급의 사람이 하나 있고, 명령은 위에서 아래로만 흐르는 구조 말입니다.
프로그래밍 자료구조 중에서는 '트리'가 대표적인 계층형 구조입니다. 트리는 정의상 부모노드와 자식노드가 일대다 관계입니다. 모든 자식노드는 직/간접적으로 하나의 부모노드에 연결되어 있고, 이 부모노드를 통해서만 접근 가능한 구조이지요.
그렇다면 '계층형 구조는 트리'라고 말해도 될까요?
저는 이 명제가 대부분의 상황과 데이터에 맞는 말이지만, 이와 다른 상황도 현실에 얼마든지 있다고 봅니다. 회사를 예로 들어 보면, 한 명의 직원이 하나의 업무에 대해 두 명 이상의 임원에게 보고해야 하는 경우가 있습니다. 물론, 이는 바람직한 업무 운영 방식이 아니기는 합니다만, 이것 또한 계층형 구조로 볼 수 있습니다. 또 다른 예로, 데이터를 분석할 때에도 어떤 데이터에 시간적 또는 논리적으로 선행하는 데이터가 둘 이상인 경우도 얼마든지 있을 것입니다.
하지만 이것은 확실하게 말할 수 있습니다. '계층형 구조에는 사이클이 없다', 또는 '사이클이 있으면 계층형 구조가 아니다'라고 말입니다. 극단적인 예로 과장이 대리에게, 대리가 주임에게 업무를 지시했는데, 이 주임이 사실은 회장님 아들이어서 다시 과장에게 업무를 암묵적으로 지시하는 상황을 생각해 봅시다. 이건 한마디로 위아래가 없는 상황, 계층을 구분할 수 없는 상태입니다.

즉 최소한, 전체 데이터 집합을 구성하는 데이터들의 높고 낮음이 한 방향으로 결정될 수 있어야 그 데이터는 계층형 구조를 가진다고 말할 수 있습니다. 그런 의미에서 계층형 구조를 가져야 하는 데이터에 사이클이 있지는 않은지 확인하는 것 역시 계층형 데이터를 다룰 때 중요한 문제 중 하나가 될 것입니다.
2. Oracle 계층형 쿼리 작성 실습
Oracle에서는 계층형 구조 데이터를 갖는 테이블을 다루기 위한 여러 가지 도구를 제공합니다.
이어지는 내용에서는 이 중 가장 기본적인 것들을 사용하는 방법을 다룹니다.
- CONNECT BY 절
- START WITH 절
- PRIOR 키워드
2.1. 테이블 CREATE
CREATE TABLE EMP (
id NUMBER,
name VARCHAR2(100),
manager_id NUMBER,
CONSTRAINT PK_EMP PRIMARY KEY(id)
);
2.2. 테이블 데이터 INSERT
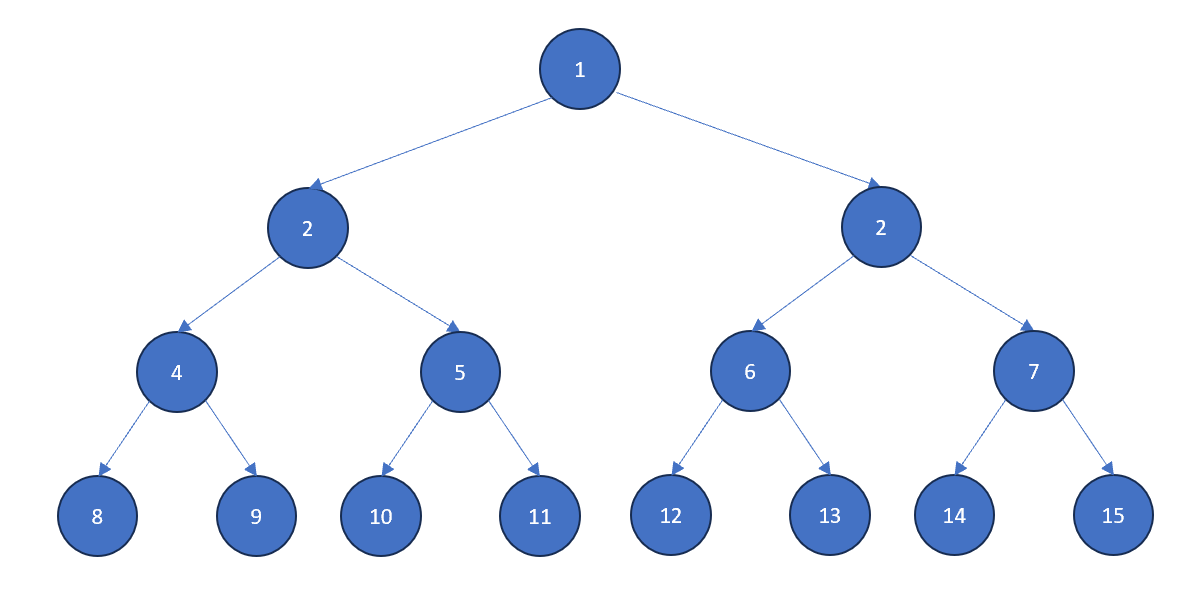
직원 17명에 해당하는 데이터를 EMP 테이블에 INSERT 합니다.
INSERT ALL
INTO EMP (ID,NAME,MANAGER_ID) VALUES (1,'EMP_1',0)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (2,'EMP_2',1)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (3,'EMP_3',1)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (4,'EMP_4',2)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (5,'EMP_5',2)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (6,'EMP_6',3)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (7,'EMP_7',3)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (8,'EMP_8',4)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (9,'EMP_9',4)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (10,'EMP_10',5)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (11,'EMP_11',5)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (12,'EMP_12',6)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (13,'EMP_13',6)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (14,'EMP_14',7)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (15,'EMP_15',7)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (16,'EMP_16',8)
INTO EMP (ID,NAME,MANAGER_ID) VALUES (17,'EMP_17',8)
SELECT * FROM DUAL;
위 데이터가 가지고 있는 계층형 구조를 그림으로 표현하면 아래와 같습니다. (화살표를 쏘는 쪽: 매니저, 받는 쪽: 일반 직원)
2.3. 실습 목표
우리의 목표는 각 직원이 보고 체계에서 몇 번째 등급인지를 보여주는 데이터를 출력하는 것입니다. 가장 상위 직급의 직원일수록 등급(LEVEL) 값이 작고(1등급), 하위 직급의의 직원일수록 값이 큽니다(4등급).
점진적 학습을 위해 의도적으로 틀린 SQL을 중간에 집어 넣었습니다.
2.4. CONNECT BY 절
CONNECT BY 절에는 부모 행과 자식 행이 연결되는 조건을 기술합니다. 예를 들어 다음과 같이 SQL을 작성해 봅시다.
```SQL
SELECT id, name, manager_id, LEVEL
FROM EMP
CONNECT BY manager_id = id;
```ID|NAME |MANAGER_ID|LEVEL|
--+------+----------+-----+
5|EMP_5 | 2| 1|
8|EMP_8 | 4| 1|
6|EMP_6 | 3| 1|
2|EMP_2 | 1| 1|
7|EMP_7 | 3| 1|
3|EMP_3 | 1| 1|
4|EMP_4 | 2| 1|
15|EMP_15| 7| 1|
1|EMP_1 | 0| 1|
11|EMP_11| 5| 1|
13|EMP_13| 6| 1|
12|EMP_12| 6| 1|
10|EMP_10| 5| 1|
14|EMP_14| 7| 1|
9|EMP_9 | 4| 1|
이 쿼리는 우리가 목표한 결과를 반환하지 않습니다. LEVEL 컬럼의 값이 모두 1인데, 이는 모든 행이 루트라는 뜻입니다. 왜 이런 일이 발생했을까요? 그 이유는 어떤 행이 루트가 되어야 하는지에 대한 정보가 쿼리에 기술되지 않았기 때문입니다. 즉, 모든 행이 루트로 취급된 것이지요.
2.5. START WITH 절
어떤 행이 루트가 되어야 하는지에 대한 정보는 START WITH 절에 기술합니다. 현재 연습용 데이터에서 루트 행의 `id` 값은 '1'이라고 정했습니다. 따라서, 위 SQL을 아래와 같이 수정해 보겠습니다.
SELECT id, name, manager_id, LEVEL
FROM EMP
CONNECT BY manager_id = id
START WITH id = 1;ID|NAME |MANAGER_ID|LEVEL|
--+-----+----------+-----+
1|EMP_1| 0| 1|
이 쿼리 역시 우리가 목표한 결과를 반환하지 않습니다. 달랑 루트 행 하나만 반환되었습니다. 왜 이런 일이 생겼을까요? 그 이유는 부모 행의 어떤 컬럼을 기준으로 자식 행을 연결할지에 대한 내용이 CONNECT BY 절에 기술되지 않았기 때문입니다.
2.6. PRIOR 키워드
CONNECT BY 절에서 어떤 컬럼이 **부모** 행의 컬럼임을 나타내기 위해서는 *PRIOR* 키워드를 앞에 붙여서 수식해 주어야 합니다. 즉, 아래와 같이 수정할 수 있습니다.
SELECT
id, name, manager_id, LEVEL
FROM EMP
CONNECT BY manager_id = PRIOR id
START WITH id = 1;
위 쿼리는 부모 행의 `id` 컬럼과 같은 값을 `manager_id` 컬럼 값으로 가지고 있는 자식 행을 연결하라고 지시합니다.
이렇게 하면, 이 쿼리는 드디어 우리가 원하는 결과를 반환합니다.
ID|NAME |MANAGER_ID|LEVEL|
--+------+----------+-----+
1|EMP_1 | 0| 1|
2|EMP_2 | 1| 2|
4|EMP_4 | 2| 3|
8|EMP_8 | 4| 4|
9|EMP_9 | 4| 4|
5|EMP_5 | 2| 3|
10|EMP_10| 5| 4|
11|EMP_11| 5| 4|
3|EMP_3 | 1| 2|
6|EMP_6 | 3| 3|
12|EMP_12| 6| 4|
13|EMP_13| 6| 4|
7|EMP_7 | 3| 3|
14|EMP_14| 7| 4|
15|EMP_15| 7| 4|
`LEVEL` 의사컬럼(pseudo-column)을 기준으로 ORDER BY 하면 아래와 같습니다.
ID |NAME |MANAGER_ID|LEVEL|
---+-------+----------+-----+
1|EMP_1 | 0| 1|
2|EMP_2 | 1| 2|
3|EMP_3 | 1| 2|
4|EMP_4 | 2| 3|
5|EMP_5 | 2| 3|
6|EMP_6 | 3| 3|
7|EMP_7 | 3| 3|
8|EMP_8 | 4| 4|
9|EMP_9 | 4| 4|
10|EMP_10 | 5| 4|
11|EMP_11 | 5| 4|
12|EMP_12 | 6| 4|
13|EMP_13 | 6| 4|
14|EMP_14 | 7| 4|
15|EMP_15 | 7| 4|
2.7. 루트 조건(시작 조건)이 명확하지 않으면 어떤 결과가 나올까?
만약 바로 위 SQL에서 START WITH 절을 빼면 어떻게 될까요? 이 경우 모든 행이 루트로 간주될 수 있고, 이에 따라 가능한 계층형 구조의 경우의 수가 모두 나옵니다. 전체 데이터를 하나의 트리로 본다면, 이 트리 안에 포함되는 모든 하위트리(subtree) 구조를 조회하는 것과 마찬가지이지요.
SELECT
id, name, manager_id, LEVEL
FROM EMP
CONNECT BY manager_id = PRIOR id;
직원4(EMP_4)를 예로 들겠습니다. 직원4는 직원1을 루트로 하는 계층구조에서는 LEVEL 3에 위치하지만, 직원2를 루트로 하는 계층 구조에서는 LEVEL2에 위치합니다. 그리고 자기 자신을 루트로 하는 경우에는 LEVEL1에 위치하게 됩니다. 그림으로 표현하면 다음과 같습니다.

단, 루트가 언제나 하나여만 하는 것은 아닙니다. START WITH 절에 조건을 어떻게 기술하는지에 따라 루트가 되는 행을 여러 개 지정할 수도 있지요. 예를 들어, 다음 쿼리는 총 몇 개 행을 반환할까요? 참고로, 아래 쿼리에 포함된 CONNECT_BY_ROOT는 계층의 루트가 되는 행의 데이터를 조회하기 위해 사용하는 연산자입니다.
SELECT id, name, manager_id, LEVEL, CONNECT_BY_ROOT(ID) AS rootid
FROM EMP
CONNECT BY manager_id = PRIOR id
START WITH id IN (1, 2)
ORDER BY rootid, level;
위 쿼리는 직원1(1번 노드)로 시작하는 계층 구조와 직원2(2번 노드)로 시작하는 계층 구조를 모두 조회합니다. 아래는 위 쿼리를 실행한 결과입니다. 실습 시작 부분에 첨부된 트리 그림을 보시고 아래 결과행이 트리의 어떤 부분에 대응하는 것인지 관찰해 보시면, CONNECT BY ~ START WITH 절 의미를 이해하시는데 도움이 되리라 생각합니다.
ID|NAME |MANAGER_ID|LEVEL|ROOTID|
--+------+----------+-----+------+
1|EMP_1 | 0| 1| 1| --- 1번 노드로 시작하는 트리
2|EMP_2 | 1| 2| 1|
3|EMP_3 | 1| 2| 1|
7|EMP_7 | 3| 3| 1|
6|EMP_6 | 3| 3| 1|
5|EMP_5 | 2| 3| 1|
4|EMP_4 | 2| 3| 1|
13|EMP_13| 6| 4| 1|
11|EMP_11| 5| 4| 1|
10|EMP_10| 5| 4| 1|
9|EMP_9 | 4| 4| 1|
8|EMP_8 | 4| 4| 1|
12|EMP_12| 6| 4| 1|
15|EMP_15| 7| 4| 1|
14|EMP_14| 7| 4| 1|
2|EMP_2 | 1| 1| 2| -- 2번 노드로 시작하는 트리
4|EMP_4 | 2| 2| 2|
5|EMP_5 | 2| 2| 2|
8|EMP_8 | 4| 3| 2|
9|EMP_9 | 4| 3| 2|
10|EMP_10| 5| 3| 2|
11|EMP_11| 5| 3| 2|
2.8. 실습 목표 정답
결론적으로, 우리가 작성하려고 했던 쿼리(= 각 직원이 보고 체계에서 몇 번째 등급인지를 보여주는 데이터를 출력하는 쿼리)는 다음과 같이 작성하시면 됩니다.
SELECT
id,
name,
manager_id,
LEVEL
FROM EMP
CONNECT BY manager_id = PRIOR id
START WITH id = 1;
3. 나가기: 계층형 데이터 다루기 - 세부사항
데이터의 계층 관계를 조회하는 것이 끝은 아닙니다. 데이터를 골랐으면 필터링도 해야 하고, 정렬도 해야 하고, 어떤 데이터가 최상위 데이터를 갖지 않는지, 어떤 데이터에서는 더 이상 계층이 이어지지 않는지 등 확인하고 싶을 수도 있고, 계층형 데이터를 가지고도 일반적인 쿼리 관련 작업을 수행할 수 있어야 합니다. 이에 대해서는, 후속 포스트에서 다루겠습니다.
오류에 대한 지적이나 질문은 댓글로 남겨 주세요. 감사합니다. :)
'SQL' 카테고리의 다른 글
| [Oracle] 계층형 쿼리 (2) (CONNECT_BY_ROOT, CONNECT_BY_LEAF, SYS_CONNECT_BY_PATH, ORDER SIBLINGS BY) (0) | 2025.09.21 |
|---|